Polyglot - Bio-inspired Exploration of Language Embedding
September, 2021 | Data Visualization, Information Retrieval, Natural Language Processing
 An Overview of Polyglot
An Overview of Polyglot
This is my master thesis project that I worked on in the first two years of my Ph.D. program at UCSC. The main idea is to combine an agent-based algorithm called Monte Carlo Physarum Machine (MCPM) to discover structures within language embedding data. I will introduce both language embedding and MCPM briefly.
Word embeddings, such as Word2Vec, GloVe, and ELMo, are vector/points generated by an algorithm. The key computational idea is to transform topological information contained in a relational graph (e.g. the context surrounding a word token, how it is used in a sentence) to geometric information encoded in a D-dimensional vector (‘embedding’) space. Embeddings have a number of interesting algebraic properties: most importantly, the contextual similarity of the embedded tokens is transformed into geometric proximity in the embedding. Because they explicitly consider the token’s context, it has been shown that embeddings contain information that can be processed to extract a range of useful properties: clustering by token usage as well as different kinds of syntactic information.
MCPM is an agent-based model inspired by the self-organizing characteristics of slime mold, initially studied by Jeff Jones. It was then modified by Burchett et al. with an additional Monte Carlo decision-making process, and was shown to be empirically accurate in predicting the pattern of the cosmic web of the universe.
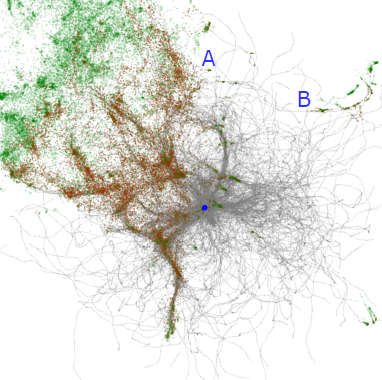 A visualization of trace-guided agent travel path (grey). Agents are spawned on the blue dot to explore green tokens. Discovered tokens are marked red.
A visualization of trace-guided agent travel path (grey). Agents are spawned on the blue dot to explore green tokens. Discovered tokens are marked red.
An intuitive way to think about MCPM is that it discovers structures by spawning a swarm of agents. The agents navigate by following the trace - a density field in a 3D grid, implemented with a 3D array. The value within each cell of the trace determines how much the agent is attracted to it. Thus, the agent’s travel trajectory is steered by the density value in the trace. The above image shows the impact of trace-guided travel. The marked region A is more thoroughly explored than B in spite of both having a similar Euclidean distance from the source. This translates to A being closer within the paradigm of optimal transport.
We also develop a web visualization tool named Polyglot. This application allows the examination of word embedding data in 3D space. In addition to 3D navigation of the scatter plot space, the application also uses colors to enable two ways of exploring the dataset: (1) coloring based on the result of MCPM and (2) coloring based on each word’s part-of-speech tag. My media-making statement provided below details the iterations we went through with the tools.